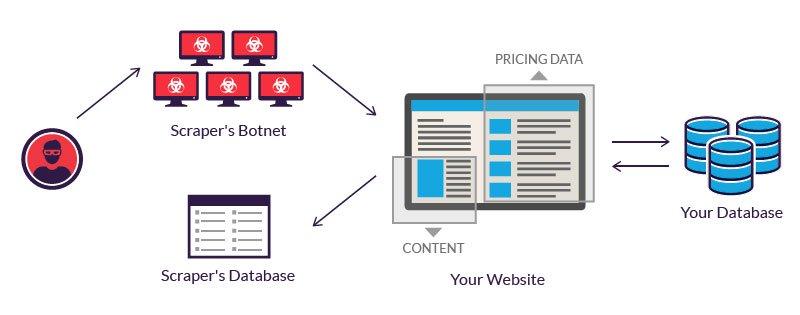
In today’s data-driven world, teh ability to extract valuable information from websites has become a game-changer for businesses, researchers, and developers alike. Imagine having the power to gather insights from the vast ocean of online content—be it competitor pricing, market trends, or customer reviews.But here’s the catch: not all websites are created equal when it comes to data scraping. The structure of a website can substantially influence your scraping success or, conversely, lead you down a frustrating path of dead ends and incomplete data. In this article, we’re going to explore how the architecture of a website affects your data scraping projects and why understanding these nuances is crucial for achieving your goals. Whether you’re a seasoned scraper or just dipping your toes into the world of data extraction, grasping the intricacies of website structures will empower you to streamline your operations and unlock a treasure trove of information. So, let’s dive in and uncover the secrets to successful data scraping!
Understanding the Basics of Website Structures for Effective Data Scraping
When embarking on data scraping projects,it’s essential to grasp the basic components of website structures. Websites are built using various technologies,and the way these elements are organized can significantly influence the success of your scraping endeavors. understanding this architecture not only enhances your ability to extract data effectively but also minimizes the risk of running into obstacles that could derail your project.
at the heart of every website lies the HTML structure, which dictates how content is displayed. scraping tools often rely on parsing HTML to locate and extract relevant data. Key areas to focus on include:
Tags: Different HTML tags serve distinct purposes. As an example, headings (h1, h2, etc.) often contain titles, while paragraph tags (
) are used for body text.
Classes and IDs: These attributes allow for targeted scraping. Using specific classes or IDs can help your scraper pinpoint the exact data you need.
Nesting: Understanding how elements are nested can enhance your scraper’s efficiency. Data frequently enough resides within multiple layers,and recognizing this hierarchy is crucial.
Another aspect to consider is JavaScript-rendered content. Many modern websites use JavaScript frameworks to dynamically load data, which can complicate scraping efforts. Here are some strategies to overcome these challenges:
Use Headless Browsers: Tools like Puppeteer or Selenium can simulate user interactions and render JavaScript-heavy websites.
API Integration: Some websites provide APIs that deliver structured data directly, bypassing the complexities of scraping.
Network Monitoring: by analyzing network requests, you can sometimes locate the sources of data that are loaded via JavaScript.
Understanding website navigation and pagination is also vital.Many sites divide their content across multiple pages, and knowing how to navigate these can make a significant difference. Consider the following:
Link Structure: Analyzing how links are structured can help automate the process of moving from one page to another.
Query Parameters: Websites often use query parameters in URLs to manage pagination, which can be leveraged for scraping.
To illustrate these points, let’s take a look at a simple table that summarizes common HTML elements relevant to data scraping:
HTML Element
Purpose
Container for other elements
Hyperlink to other pages
Structure data in tabular format
Displays images
Ultimately, a solid understanding of website structures can empower you to execute scraping projects with greater precision and efficacy. By being aware of how data is organized, whether it’s through HTML tags, JavaScript elements, or navigation systems, you can streamline your scraping process and maximize your results.
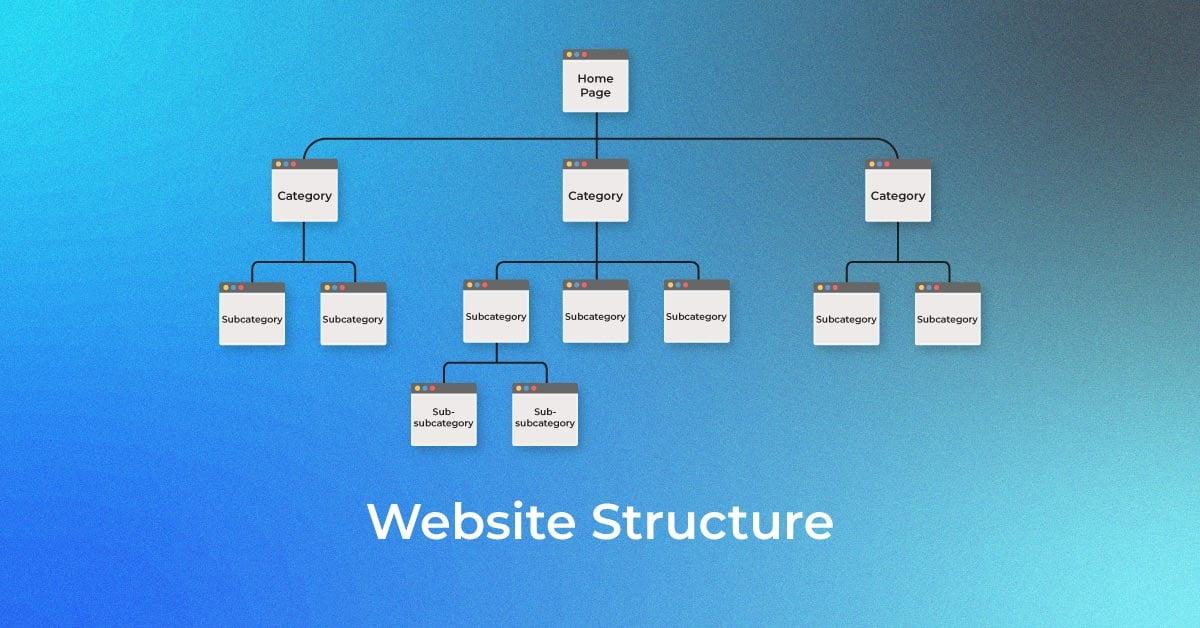
Why a Clear Hierarchical Structure Can Make or Break Your Project
A well-defined hierarchical structure on a website is not just a matter of aesthetics; it plays a crucial role in determining the success of data scraping projects. When a site is organized intuitively, it enhances the efficiency of the scraping process, allowing for smoother navigation and better data retrieval.
Consider the following benefits of a clear hierarchy:
Improved Accessibility: A structured layout ensures that all pages are easy to locate. This is essential for scraping tools that rely on predictable patterns to harvest data.
Faster Processing: When data is structured logically, scraping algorithms can process information faster, minimizing the time it takes to gather necessary data.
Reduced Errors: A clear hierarchy minimizes the risk of missing crucial data points or misinterpreting information, which is vital for accurate data analysis.
Moreover, websites with a well-thought-out sitemap not only serve human users better but also cater to scraping bots effectively. For example, a site with a clear category structure allows scrapers to target specific sections without digging through irrelevant content. This can drastically cut down on the amount of unneeded data processed.
Let’s illustrate this with a simple comparison of two website structures:
Website A (Poor Structure)
Website B (Clear Structure)
Home > Blog > Article > Sub-Article
Home > Products > Electronics > Phones
Confusing navigation leads to missing data.
Logical flow allows targeted scraping.
More time spent filtering irrelevant content.
Fast data extraction with clear paths.
a well-structured website not only benefits user experience but is paramount for the effectiveness of data scraping projects. By taking the time to ensure that your website’s hierarchy is clear and logical, you set a strong foundation for successful data extraction efforts. Ultimately, this can lead to faster insights, better decision-making, and a more efficient workflow.
The Role of HTML Markup in Simplifying Your Scraping Process
When it comes to data scraping, understanding the HTML structure of a website is crucial. HTML markup serves as the backbone of web content, providing a clear framework that allows both users and scrapers to navigate through data effectively. By comprehending how elements are nested and organized,you can significantly enhance the efficiency of your scraping efforts.
Consider the following aspects of HTML markup that can simplify your scraping process:
Semantic Elements: websites that utilize semantic HTML elements, such as , , and , help to define the purpose of different sections. This clarity allows scrapers to target specific areas of interest without sifting through irrelevant data.
consistent Class Names: When developers adhere to consistent naming conventions for CSS classes,it makes it easier for scrapers to identify similar types of data. For instance, if all product listings use the class .product-item, your scraper can efficiently loop through these elements to gather necessary information.
Data attributes: Many modern web pages incorporate custom data attributes, like data-price or data-id, which can be a goldmine for scrapers. These attributes provide direct access to significant information without the need to parse through additional HTML tags.
Additionally, understanding the structure of a website can help you avoid common pitfalls. For example,if a site employs a combination of JavaScript to load content dynamically,it’s essential to recognize that the data might not be present in the initial HTML response. Familiarity with the site’s markup can guide you in choosing the right tools, such as headless browsers, to capture the data effectively.
HTML Element
Purpose
General container for HTML elements.
Inline container for text and other inline elements.
Unordered list, useful for collections of items.
Displays data in a tabular format.
a solid grasp of HTML markup not only streamlines your scraping process but also empowers you to make more informed decisions about your scraping strategy. By leveraging well-structured HTML, you can target data more effectively, minimize errors, and ultimately enhance the success of your data scraping projects.
Identifying Key Data Points: How Structure Influences Content Extraction
When diving into the world of data scraping, understanding the structure of a website is crucial. A well-organized site presents a clear path for scrapers, helping them extract relevant data efficiently. Here’s a closer look at how website structure plays a pivotal role in identifying key data points.
First and foremost, the hierarchy of a website can significantly affect how data is accessed. Websites that follow a clean, logical structure often categorize content in a way that makes it easier for scraping tools to pinpoint specific information. For example, consider the following structural elements:
Navigation Menus: Clear menu items that direct users to various sections.
Breadcrumbs: These can help scrapers understand the path taken within the site, providing context for the data.
Consistent Layouts: Pages that maintain a uniform format make it easier to predict where data will appear.
Moreover, the use of HTML tags plays a vital role in content extraction. Websites that properly utilize semantic HTML elements—like
, , and —allow scrapers to navigate the content more intuitively. This can be especially beneficial for identifying:
Headings: These provide context and structure to the information.
Lists: Data presented in lists is often easier to extract and categorize.
Tables: Well-structured tables can directly translate to data arrays, making extraction straightforward.
Consider this simple example of a table structure that enhances data extraction:
Data Type
Importance
Text Content
High
Images
Medium
Metadata
High
Lastly, ensuring that a website is mobile-friendly can also influence the success of data scraping projects. Responsive designs often lead to consistent data structures across different devices,making it easier to extract data without unnecessary complications. When scrapers encounter a site that adapts well to various screen sizes, they can frequently enough find the same key data points in predictable locations.
Ultimately, savvy web developers and content creators can facilitate data extraction by maintaining a clear, logical structure and using best practices in HTML. This not only benefits scrapers but also enhances user experience, creating a win-win situation for all parties involved.
Navigating Complex Sites: Tips for Scraping from Multi-layered Structures
Scraping data from complex websites can often feel like navigating a maze, especially when dealing with multi-layered structures.The key to successful data extraction lies in understanding the layout and behaviour of the site you’re targeting. Here are some handy tips to help you conquer these intricacies:
Map the Structure: Take the time to create a visual representation of the website’s architecture. This will help you identify critically important nodes and paths for your scraping project.
Use Browser Developer Tools: Inspect elements,view network requests,and monitor API calls to gain insights into how the website organizes its data.
Identify patterns: Look for consistent patterns in URLs and data presentation. Often, you’ll find that similar data is grouped together, which makes it easier to extract.
Stay Flexible: Websites can change unexpectedly. Ensure your scraping script can adapt to minor variations in structure without breaking.
Consider Pagination: Many sites use pagination to display large datasets.Make sure to account for this in your scraping logic to capture all relevant information.
Additionally, it’s essential to consider the technology stack the website uses. Sites built with frameworks like React or Angular may load data dynamically. In such cases, employing headless browsers or tools like Selenium can be invaluable. These tools simulate user interactions, allowing you to capture data that isn’t immediately rendered in the HTML source.
Don’t forget about the importance of legal and ethical guidelines when scraping data. Be sure to check the website’s robots.txt file to understand their scraping policies. Respecting these rules not only helps you stay on the right side of legality but also fosters goodwill in the data scraping community.
If you’re dealing with especially intricate sites, consider using a structured approach such as:
Step
Description
1. Analyze
Study the website’s layout and data flow.
2.Select Tools
Choose the right scraping tools and libraries.
3. Implement
Develop and test your scraping script.
4. Validate
Check the accuracy of the extracted data.
By keeping these strategies in mind, you can enhance your chances of successfully scraping data from complex, multi-layered websites. Embrace the challenge, and you’ll find that every obstacle is an opportunity to refine your approach and expand your skill set.
How to Use Sitemaps to Your Advantage in Data Scraping
Sitemaps are more than just a roadmap for search engines; they can be a goldmine for data scraping projects. By understanding how to leverage these documents, you can streamline your scraping efforts and extract valuable data more efficiently. Here are some strategies to make sitemaps work for you:
Identify Target Pages: Sitemaps list all the URLs of a website,making it easier to pinpoint the specific pages you want to scrape. This can save a significant amount of time compared to manual browsing.
Understand Structure and Hierarchy: Analyzing the sitemap allows you to grasp the website’s structure. Knowing which sections are most important helps prioritize your scraping strategy, focusing on high-value pages first.
Monitor Updates: Many sitemaps are updated regularly. By keeping an eye on changes, you can adjust your scraping schedule to capture fresh data promptly.
Filter out Unwanted URLs: Use the information in sitemaps to filter out URLs that don’t align with your data needs, such as duplicate or irrelevant pages, enhancing your scraping process.
When you’re ready to start scraping, consider using tools that can read sitemaps automatically. Many modern scraping frameworks come equipped with features that allow you to pull data directly from sitemap URLs, providing a seamless integration into your workflow. This not only speeds up the process but also reduces the chances of errors.
Additionally, here’s a simple table to illustrate how sitemaps can enhance your scraping efficiency:
Benefit
Description
Time-Saving
direct access to all URLs eliminates the need for manual search.
Focused Scraping
Helps prioritize the most relevant pages for data extraction.
Regular Updates
Stay updated with new content and changes on the website.
Incorporating sitemaps into your data scraping strategy not only boosts efficiency but also enhances the overall quality of the data you gather. By utilizing these insights, you can turn potential challenges into opportunities, making your scraping projects more successful and insightful.
Handling Dynamic Content: Strategies for Scraping JavaScript-heavy Sites
When it comes to scraping JavaScript-heavy websites, customary methods often fall short due to the dynamic nature of their content. These sites utilize frameworks like React, Angular, or Vue.js,which render content on the client side. Consequently, the data you need might not be available in the initial HTML response. To tackle this challenge, consider employing the following strategies:
Headless Browsers: Tools like puppeteer or Selenium can simulate a real user’s interaction with the webpage. They execute JavaScript and allow you to capture the dynamically generated content as if you were browsing manually.
API Exploration: Many JavaScript-heavy sites have underlying APIs that serve the data. Use tools like Postman or your browser’s developer tools to inspect network calls and identify endpoints that deliver the desired data.
DOM Manipulation: If you can access the DOM after JavaScript execution, use libraries like cheerio (in Node.js) to parse the rendered HTML and extract the necessary information.
It’s also essential to understand the timing of when content loads. Some websites load data asynchronously, meaning the content may not be available immediately. Here are a couple of techniques to consider:
Wait Strategies: Implement wait strategies in your scraping scripts to give the page time to load fully. This can be done using functions that pause execution until certain conditions are met, such as specific elements being present in the DOM.
Event Listeners: If you’re dealing with single-page applications (SPAs), listen for specific events that may signal the completion of data loading. This can help streamline your scraping process and ensure you capture all relevant data.
moreover,remember that effective data scraping is not just about technology; it’s also about strategy. Here’s a speedy comparison of various scraping methods:
By selecting the right approach and being mindful of the website’s architecture, you can significantly enhance the success of your scraping projects. Adapting your strategy based on the site’s behavior not only saves time but also ensures that you gather accurate and comprehensive data. With the right tools and techniques, even the most JavaScript-heavy sites can become a treasure trove of valuable information.
Best practices for Respecting Website Policies While Scraping
When embarking on data scraping projects, it’s essential to prioritize ethical practices that respect website policies. Ignoring the guidelines set by the website can not only damage your reputation but also lead to legal consequences. Here are some best practices to consider:
Read the Robots.txt File: Before scraping, always check the /robots.txt file of the website. This file outlines the areas of the site that are off-limits to crawlers and scrapers.Respect the rules stated here to avoid any unwanted conflicts.
Understand the Terms of Service: Familiarize yourself with the website’s Terms of Service. These policies usually contain information about data usage, copyright, and scraping permissions.Compliance is key!
limit Request Rates: To avoid overwhelming the server, implement a reasonable delay between requests. This not only helps you stay under the radar but also ensures that you do not disrupt the user experience for others.
use API When Available: Many websites offer APIs for developers. If an API is available, utilize it instead of scraping the website. This approach is typically more efficient and aligns with the site’s intended use of its data.
Attribute Your Sources: If you use data that you’ve scraped, be sure to give proper credit. This practice builds trust and demonstrates respect for the original content creators.
To further illustrate the importance of these practices, consider this simple comparison of ethical versus unethical scraping behaviors:
Ethical Scraping
Unethical Scraping
Follows robots.txt guidelines
Ignores robots.txt rules
respects data usage policies
Uses data without permission
Utilizes available APIs
Scrapes directly from the website
Approaches scraping with clarity
scrapes covertly without attribution
By adhering to these best practices, you’re not just ensuring the success of your data scraping projects, but also fostering a respectful and sustainable relationship with the websites you rely on. This mindset not only benefits you as a scraper but enhances the overall health of the digital ecosystem.
Tools and Techniques to Overcome structural Challenges in Data Scraping
When diving into the world of data scraping, understanding the structure of the target website is crucial. Various tools and techniques can enhance the effectiveness of your extraction efforts, especially when faced with intricate layouts or anti-scraping measures. Here are some essential strategies to consider:
DOM Inspection Tools: Utilize browser extensions like Web Developer or XPath Helper to inspect the Document Object Model (DOM) of web pages. This allows you to identify the right HTML elements to target.
Headless Browsers: Tools like Puppeteer or Playwright enable you to navigate complex web pages and execute JavaScript, ensuring you retrieve all dynamic content.
Data Extraction Libraries: Leverage libraries such as Lovely Soup for Python or Cheerio for Node.js. These libraries simplify the process of parsing HTML and extracting relevant data.
apis and RSS Feeds: Always check for available APIs or RSS feeds. They often provide a more stable and straightforward method for data retrieval compared to scraping.
Implementing proxies can also be a game-changer in avoiding blocks from websites that monitor scraping activities.here’s a quick comparison of proxy types:
Proxy Type
Pros
Cons
Residential Proxies
Less likely to be blocked
More expensive
Datacenter Proxies
Cost-effective
Higher chance of being blacklisted
Rotating Proxies
Dynamic IP rotation
can be slower
Another technique to enhance your scraping capabilities is utilizing data cleaning tools. After extraction, data often comes with noise or irrelevant information. Tools like OpenRefine help cleanse and transform your data, making it more usable for analysis.
don’t overlook the importance of error handling. Building robust error-handling routines in your scraping scripts ensures that your project can gracefully manage unforeseen challenges.This might include retries for failed requests or logging errors for later analysis.
Case Studies: Successful Data Scraping Projects and Their Website Structures
Data scraping is an art that intertwines the technical aspects of web architecture with the analytical prowess of interpreting data. To illustrate how different website structures can influence the success of data scraping, let’s delve into some compelling case studies that highlight various approaches and their outcomes.
Case Study 1: E-Commerce Giant
In the world of e-commerce, data scraping has become essential for competitive analysis and price monitoring. One successful project involved scraping a well-known online retailer. The website employed a complex architecture with multiple layers of navigation and AJAX loading for product details. By mapping out the site structure using tools like XPath and CSS selectors, the scraping team was able to extract:
Product names
Prices
Customer reviews
This project not only provided insights into pricing strategies but also enabled the client to adjust their offerings based on consumer feedback.
Case Study 2: real Estate Listings
A successful scraping initiative in the real estate sector involved gathering property listings from a popular local site. The website was designed with a straightforward HTML structure,making it easier to navigate through the property categories. This simplicity allowed the scraping tool to efficiently pull in:
In another scenario, a news aggregation platform sought to scrape articles from various news websites. These sites frequently enough employed dynamic content loading and anti-scraping measures, which presented significant challenges. however, by analyzing the Document Object Model (DOM) and employing techniques like headless browser automation, the team successfully gathered:
Headlines
Article text
Publication dates
This case highlighted the importance of understanding website behavior and structure, enabling the client to curate timely news feeds for their audience.
Project Type
Website Structure
Data Scraped
Insights Gained
E-Commerce
Complex, AJAX-based
Pricing, Reviews
Competitive Strategies
Real Estate
Simple HTML
Listings, Agent Info
Market Trends
News Aggregation
Dynamic Loading
Articles, Dates
Content Curation
the success of these projects demonstrates that understanding the underlying structure of a website is pivotal in crafting effective scraping strategies. By tailoring scraping techniques to the specific architecture of each site, businesses can unlock valuable data that drives informed decision-making.
Future Trends: How Evolving Website Designs Will Impact Data Scraping
The landscape of website design is continuously evolving, and these changes are poised to have significant implications for data scraping. As more businesses recognize the importance of user experience, we are witnessing a shift towards dynamic and interactive web elements. Features such as single-page applications (SPAs) and progressive web apps (PWAs) can enhance user engagement but may also complicate data extraction processes.
JavaScript frameworks like React, Angular, and vue.js are becoming increasingly popular for building websites. While these frameworks provide a seamless user experience, they frequently enough load content asynchronously, making traditional scraping techniques less effective. Scrapers may need to adapt by utilizing headless browsers or implementing solutions that can handle JavaScript rendering to successfully extract data.
Furthermore, the rise of API-driven advancement is changing the way data is accessed. Websites are increasingly offering APIs for third-party developers, which can simplify the data extraction process. However, this trend also raises concerns regarding data accessibility and the potential for stricter rate limits or authentication barriers.Consequently, scrapers must remain agile, continuously adapting their methods to align with these evolving access protocols.
As websites prioritize mobile responsiveness, the adoption of frameworks like Bootstrap and Tailwind CSS is becoming widespread. While these tools enhance visual appeal and functionality, they can also introduce complexity in the underlying HTML structure.To navigate these changes effectively, data scraping tools must evolve to parse through intricate layouts, ensuring that valuable information is not lost amidst design enhancements.
The increasing integration of AI and machine learning in website design also holds implications for data scraping. These technologies can personalize content and dynamically adjust layouts based on user behavior, creating a moving target for scrapers. Future-proofing scraping strategies may involve leveraging AI tools that can mimic human browsing behavior, adapting in real-time to changing web environments.
Website Design Trend
Impact on Data Scraping
Dynamic Content Loading
Requires advanced scraping techniques, such as headless browsers
API Utilization
may simplify data extraction but introduces access restrictions
Mobile Responsiveness
Increases complexity in HTML structure, affecting data accessibility
AI-driven Personalization
Presents challenges in targeting static scraping strategies
As we look ahead, it’s clear that data scraping techniques must evolve in tandem with these shifting website trends. By staying informed and adaptable, businesses can continue to extract valuable insights from web data, even as the digital landscape transforms before our eyes.
Frequently Asked Questions (FAQ)
Q&A: How Website Structures Impact the Success of Data Scraping Projects
Q: what exactly do we mean by “website structure”? A: Great question! When we talk about website structure, we’re referring to how a site is organized and how its content is arranged. This includes elements like HTML tags, URLs, and the use of classes or IDs in the code. A well-structured website is easier for both users and scraping tools to navigate.
Q: Why is website structure so important for data scraping? A: Simply put, the easier a website is to understand, the easier it is to scrape. A clear structure allows scraping tools to locate and extract data efficiently. If a website is poorly structured, it can lead to missed data, inaccurate scraping, or even tool failures, which ultimately impacts the success of your project.
Q: Can you give an example of a good website structure? A: Absolutely! Think of an e-commerce site with clearly defined categories, products, and filters. each product page has a consistent layout with structured data like prices, descriptions, and images all neatly organized. This makes it a breeze for scraping tools to pull the relevant information without getting lost in the chaos.
Q: What about websites that use a lot of JavaScript – how does that affect scraping? A: Websites that rely heavily on JavaScript can complicate scraping since the data may not be directly available in the page’s HTML. Rather, it might be loaded dynamically after the page has initially rendered. In these cases, you need more advanced scraping techniques, like using headless browsers or APIs, to access the data effectively. Understanding a site’s structure can help you determine the best approach.
Q: Are there specific structures that make scraping easier or harder? A: Definitely! websites that use semantic HTML, proper headings, and clear class names are much easier to scrape. On the other hand, sites with inconsistent layouts, heavy use of AJAX, or endless scrolling can create hurdles. The more predictable and logical the structure, the better your chances of successfully extracting the data you need.
Q: How can I assess the structure of a website before starting a scraping project? A: You can start by inspecting the page’s HTML using your browser’s developer tools. Look for patterns in the code and see how the data is organized. tools like XPath or CSS selectors can also help you determine how to access specific data points. the more you understand the layout, the smoother your scraping project will be.
Q: What can I do if I encounter a poorly structured site? A: If you’re dealing with a poorly structured site, don’t lose hope! You may need to get creative.Adjust your scraping strategy, perhaps use a combination of different tools, or even write custom scripts to navigate the chaos. Sometimes, a little extra effort in understanding the structure can lead to great rewards in data quality.
Q: Why should I care about the success of my data scraping projects? A: The success of your data scraping projects can significantly impact your business or research outcomes. Accurate and timely data can drive informed decisions, improve insights, and ultimately lead to better strategies. Investing time to understand the website structure will pay off in data quality and efficiency, making your scraping endeavors much more fruitful.
Q: Any final tips for ensuring a successful data scraping project? A: Definitely! Always start with a clear plan. Research the website and its structure, choose the right tools for the job, and be prepared to adapt your approach. Pay attention to legal and ethical guidelines when scraping data, and make sure to respect website terms of service. With the right planning,your scraping projects can be highly successful!
The Way Forward
the structure of a website plays a pivotal role in the success of your data scraping projects. Whether you’re gathering insights for market research, tracking competitors, or collecting data for analytical purposes, understanding how a site’s architecture works can save you time, resources, and a lot of frustration.
Think of it this way: a well-organized website acts like a well-marked highway, guiding your scraping tools to the data you need without detours or roadblocks. Conversely, a disorganized site can feel like navigating through a maze, leading to missed opportunities and incomplete data sets.
So,before diving into your next scraping endeavor,take a moment to analyze the website’s structure. Look for clean URLs, consistent patterns, and accessible data points.Investing this time upfront will pay off in spades, giving you a smooth, efficient scraping experience and, ultimately, better results.
Remember, successful data scraping isn’t just about the tools you use; it’s also about how you approach the data you want to collect. With the right strategies and a keen understanding of website structures,you can unlock a treasure trove of information that fuels your projects and drives your goals forward. Happy scraping!